
Amazonで売上を伸ばし続けるためには、データに基づいた意思決定が不可欠です。セラーセントラル、ベンダーセントラル、Amazon広告コンソール、AMC――Amazonには膨大なデータが存在しますが、それらを分析に使える形で一か所に集約し、継続的に更新できる仕組みを持っている企業はそれほど多くありません。
「データは取れているが、毎回手作業でCSVを加工するので時間がかかる」「売上データと広告データを突き合わせて分析したいが、フォーマットが違って結合できない」「過去データを遡ろうとしたら、もう取得期限が過ぎていた」――こうした課題に心当たりがある方は、分析の「やり方」ではなく「環境」に問題がある可能性があります。
本記事では、Amazonにおけるデータ分析の前提となる「分析環境の構築」に焦点を当てます。どのデータソースから何を取得し、どう収集・保管・統合すればよいのか。セラーとベンダーの両方を対象として、環境構築の全体像を体系的に整理します。
なお、構築した環境をどのように分析やアウトプットに活用するかについては、続編の「分析・アウトプット編」で詳しく解説する予定です。
目次
なぜ「分析環境」の構築が必要なのか
Amazonのセラーセントラルやベンダーセントラルには、売上・広告・在庫・検索トレンドなど、多彩なレポート機能が備わっています。管理画面上でデータを確認するだけなら、特別な環境構築は不要に思えるかもしれません。
しかし実際に「データを使って意思決定する」段階に進むと、管理画面だけでは以下のような限界に直面します。
| 課題 | 具体的な状況 |
|---|---|
| 過去データの保持期限 | セラーセントラルのビジネスレポートは過去2年分、広告レポートは過去60日〜90日分しか遡れない。ベンダーセントラルも同様にレポートごとに保持期間が異なる |
| クロス分析ができない | 売上データと広告データは別画面・別フォーマット。「この商品の広告費に対して利益はいくらか」を出すにはデータの結合が必要 |
| 手動ダウンロードの限界 | 週次・月次のレポート作成のたびにCSVを手動で取得し、Excelで加工する作業が発生。ASIN数が増えると工数が膨大になる |
| 属人化 | Excelの加工手順や集計ロジックが特定の担当者しか分からず、引き継ぎやチェックが難しい |
つまり、「データはあるのに分析できない」「分析しているが再現性がない」という状態が生まれます。これを解消するのが分析環境の構築です。
Amazonマーケティングにおけるデータ活用は、大きく3つのステップに分かれます。
1. 環境構築(データの収集・保管・統合の仕組みを作る)→ 2. 分析(データから示唆を得る)→ 3. 施策実行(分析に基づいてアクションを起こす)
最初のステップである環境構築が整っていなければ、その先の分析も施策実行もままなりません。本記事ではこのステップ1「環境構築」を徹底的に掘り下げます。
Amazonで取得できるデータソースの全体像
まず、環境構築の前提として「そもそもAmazonからどのようなデータが取得できるのか」を整理しましょう。セラーとベンダーでは取得できるデータの種類や名称が異なるため、両者を比較しながら見ていきます。
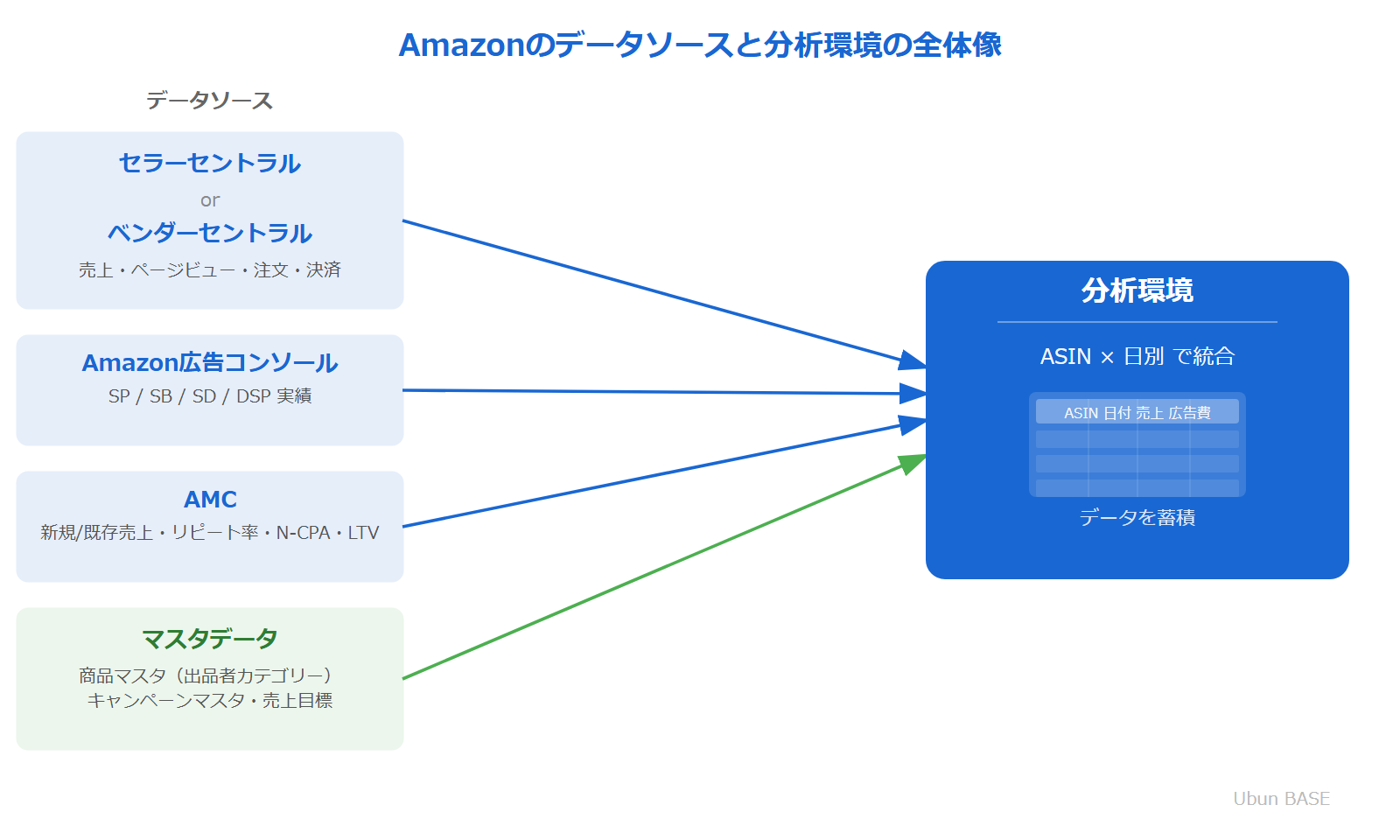
セラーセントラルのレポート群
セラー(出品者)がセラーセントラルから取得できる主なレポートは以下の通りです。
| レポート種別 | 主な内容 | 主なKPI |
|---|---|---|
| ビジネスレポート | 商品ページのアクセス状況・売上 | セッション数、ページビュー、CVR(ユニットセッション率)、注文売上 |
| 注文レポート | 注文明細・返品・返金 | 注文数、返品率、返金額 |
| 決済レポート | 入金・手数料の内訳 | 販売手数料、FBA手数料、入金額 |
| 広告レポート | SP/SB/SDキャンペーン実績 | インプレッション、クリック、ACOS、ROAS |
ベンダーセントラルのレポート群
ベンダー(メーカー・卸売業者)がベンダーセントラルから取得できるレポートは、セラーとは異なる体系になっています。
| レポート種別 | 主な内容 | 主なKPI |
|---|---|---|
| リテール分析(Retail Analytics) | 売上・出荷・在庫状況 | 受注済み売上、発送済み売上、発送済み原価、グランスビュー |
| トラフィック診断 | 商品ページへのトラフィック | グランスビュー、転換率 |
| カタログレポート | 商品情報の品質 | コンテンツスコア、画像数、A+コンテンツ有無 |
| 広告レポート | SP/SB/SDキャンペーン実績 | インプレッション、クリック、ACOS、ROAS |
ベンダーセントラルで特に注意が必要なのは、売上データが複数の指標に分かれている点です。セラーセントラルでは「売上(注文売上)」が1つの指標ですが、ベンダーセントラルでは以下の3つの売上指標が存在します。
| 指標 | 意味 |
|---|---|
| 受注済み売上 | 消費者がAmazonで注文した金額(小売価格ベース)。注文時点で計上されるが、キャンセル等で変動する |
| 発送済み売上 | 実際に出荷が完了した金額(小売価格ベース)。受注済み売上からキャンセル分を除いた確定値に近い |
| 発送済み原価 | 出荷された商品の原価(ベンダーがAmazonに卸した価格ベース)。利益計算に必要な指標 |
どの「売上」を基準にするかで数値が大きく変わるため、分析環境の設計段階でどの指標をKPIとして採用するか決めておく必要があります。
また、ベンダーの中でも「メーカー」と「お取引業者(ディストリビューター)」では、ベンダーセントラルで取得できるデータの範囲が異なります。メーカーはリテール分析の全項目にアクセスできるケースが多い一方、お取引業者は一部のレポートや指標が制限されることがあります。自社がどちらのアカウント種別に該当するかを確認し、実際に取得可能なデータ範囲を把握したうえで環境を設計しましょう。
セラーとベンダーの指標の違い
セラーとベンダーでは同じ指標でも名称や定義が異なるケースが多く、これが環境構築を複雑にする大きな要因です。
たとえば「ページビュー」という指標一つをとっても、セラーセントラルでは該当ASINの商品ページに対する全ページビューがカウントされるのに対し、ベンダーセントラルの「グランスビュー」は自社がカートボックスを取得している状態でのページビューのみが計上されます。同じ「ページの閲覧数」のように見えて、実際には異なる母数のデータであるため、単純な比較はできません。
さらに、セラーセントラルにはページビューに加えて「セッション数」(同一ユーザーの連続アクセスを1としてカウント)という指標もあります。売上の定義についても、セラーは「注文売上」の1種類に対し、ベンダーは「受注済み売上」「発送済み売上」「発送済み原価」の3種類が存在します。環境構築の段階で、これらの定義の違いを正確に把握しておくことが重要です。
Amazon Marketing Cloud(AMC)
AMC(Amazon Marketing Cloud)は、Amazonが提供するクラウドベースのデータクリーンルームです。セラー・ベンダーを問わず、スポンサー広告(SP/SB/SD)のみの出稿でも利用可能です。DSPを利用していなくても、スポンサー広告のデータを活用した高度な分析やオーディエンス作成ができます。
AMCの最大の特徴は、個々のユーザーレベルの広告接触データや購買データにSQLでアクセスできる点です。通常の広告レポートでは確認できない、セラーセントラルやベンダーセントラル、広告コンソールでは取得できない独自のデータを扱うことができます。
分析環境の構築という観点では、AMCのデータは「定期的に蓄積してモニタリングすべきデータ」と「必要なときに都度取得すればよいデータ」に分けて考えるのがポイントです。
定期的に蓄積・モニタリングすべきデータ(AMCでしか取れない指標):
- 新規顧客 / 既存顧客の売上比率:ブランド新規(NTB)の獲得状況を継続的に追跡
- N-CPA(新規顧客獲得単価):新規1人あたりの広告コストの推移
- リピート率:初回購入者のうち再購入に至った割合の変化
- LTV(顧客生涯価値)/ ARPU(ユーザー平均売上):顧客1人あたりの中長期的な売上
これらはAMCでしか取得できない指標であり、定期的にクエリを実行して時系列データとして蓄積することで、マーケティング施策の効果を中長期で検証できます。
必要なときに都度分析すればよいデータ:
- クロスチャネル分析:SP・SB・SD・DSPをまたいだユーザーの広告接触パスを追跡
- 併売分析:商品間の購買相関を調査
- オーディエンス作成:分析結果を基にしたカスタムオーディエンスを作成し、広告配信に直接活用
こうしたスポット分析は、特定の施策を検討するタイミングで都度AMCからデータを取得すれば十分です。すべてのデータを常時蓄積する必要はなく、モニタリング指標の定期蓄積 + スポット分析の都度実行という使い分けが効率的です。
AMCは分析環境という観点では最も強力なデータソースですが、SQLの知識が必要なことや、データの保持期間(過去12.5ヶ月)に制限があることは認識しておく必要があります。AMCの基本的な機能についてはAMC入門:知っておきたい基本機能もご参照ください。
Amazon Ads API / SP-API
これまで紹介したデータの多くは、API(Application Programming Interface)経由でプログラムから自動取得することも可能です。
| API | 対象 | 取得できるデータ |
|---|---|---|
| SP-API(Selling Partner API) | セラー・ベンダー共通 | 注文・在庫・カタログ・決済レポートなど |
| Amazon Ads API | セラー・ベンダー共通 | SP/SB/SD/DSPの広告レポート・キャンペーン管理。AMC APIもAds APIの一部として提供されており、SQLクエリの実行・結果取得・オーディエンス管理が可能 |
APIによるデータ収集は自動化の要ですが、開発にはOAuth 2.0認証の実装やレート制限への対応など、専門的なエンジニアリングスキルが求められます。この点については次のセクションで詳しく解説します。
データソース全体マップ
ここまで紹介したデータソースを、セラー・ベンダーそれぞれの利用可否も含めて一覧にまとめます。
| データソース | セラー | ベンダー | 主な取得方法 | 更新頻度 |
|---|---|---|---|---|
| ビジネスレポート / リテール分析 | ○ | ○ | 管理画面 / SP-API | 日次 |
| 注文・決済レポート | ○ | △(発注レポート) | 管理画面 / SP-API | 日次〜月次 |
| 広告レポート(SP/SB/SD) | ○ | ○ | 広告コンソール / Ads API | 日次 |
| AMC | ○(広告出稿者) | ○(広告出稿者) | AMCコンソール / Amazon Ads API | 任意(SQL実行時) |
この全体像を把握したうえで、次に「これらのデータをどう収集するか」を見ていきましょう。
データ収集の3つのアプローチ
Amazonのデータを収集する方法は、大きく3つに分けられます。それぞれにメリット・デメリットがあり、組織の規模やリソースに応じた選択が必要です。
ただし、どのアプローチを選ぶにしても、まず理解しておくべきAmazonのデータ収集における構造的な課題があります。
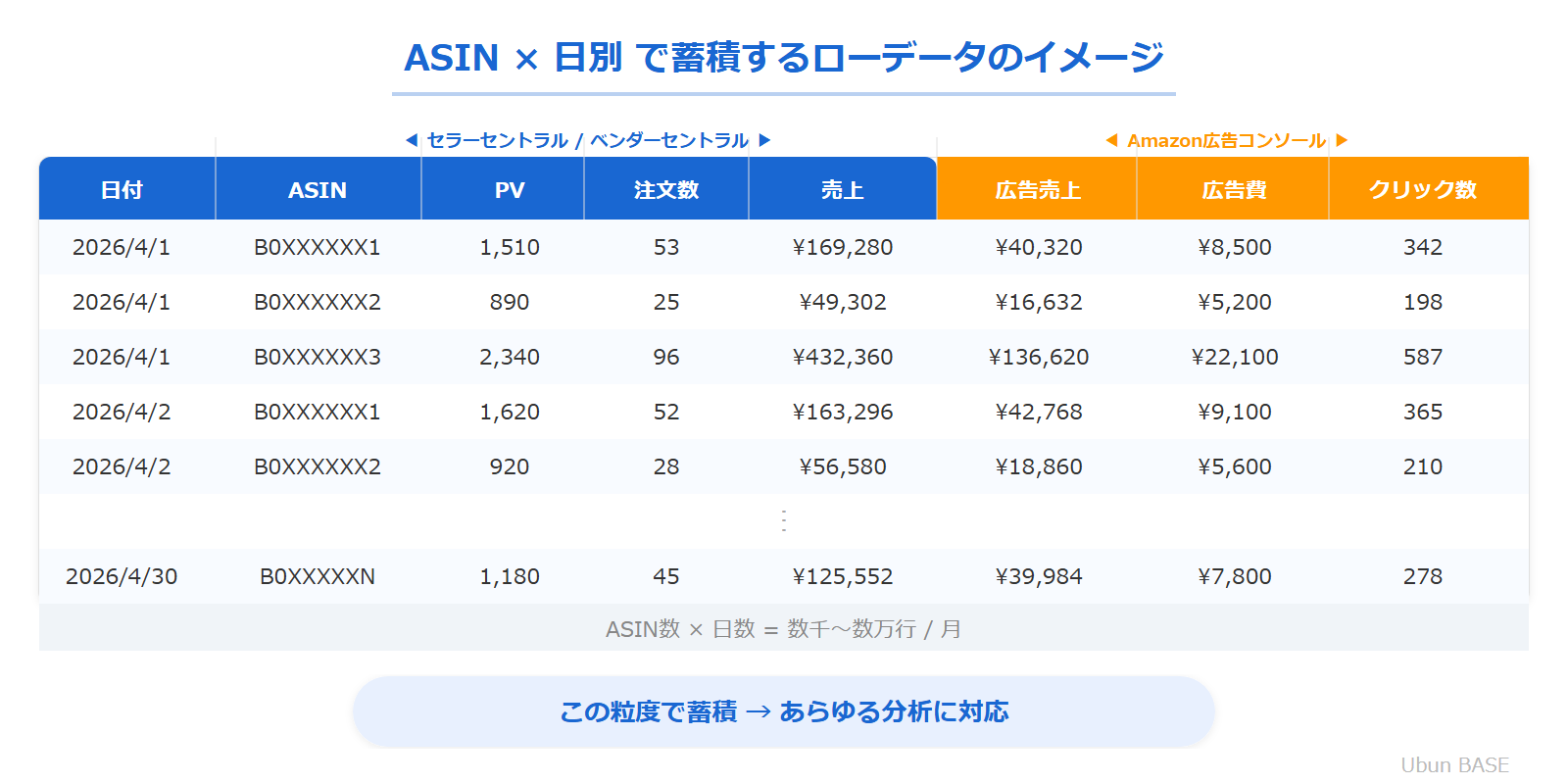
Amazonデータ収集の最大のハードル:「ASIN×日別」を維持し続ける難しさ
前のセクションで「ASIN×日別でデータを蓄積すべき」と説明しましたが、実はこれがデータ分析環境を構築するうえで最大の負担になります。
セラーセントラルやベンダーセントラルの管理画面では、ASIN×日別のデータを一括でダウンロードすることができません。1日分のレポートには全ASINのデータが含まれますが、日別データを取得するには1日ずつ日付を指定してダウンロードする必要があります。過去30日分のデータが欲しければ30回のダウンロード操作が必要で、これをビジネスレポート・広告レポートなど複数のレポート種別に対して行うと、操作回数はさらに膨れ上がります。
さらに厄介なのは、過去のデータが変動し続けるという点です。返品・返金が発生すると、注文日時点の売上データが遡って修正されます。つまり、「昨日のデータを今日取得する」だけでは不十分で、過去数日〜数週間分のデータも定期的に再取得して更新し続ける必要があるのです。
この「大量のASIN × 長期間のデータ × 継続的な再取得」という三重の負荷こそが、Amazonのデータ分析環境を自前で構築・運用することの最大のハードルです。手動運用ではすぐに破綻し、API自社開発でも相応の設計・運用コストがかかります。
アプローチ1:手動ダウンロード
セラーセントラルやベンダーセントラル、広告コンソールの管理画面からCSVを手動でダウンロードする方法です。もっとも手軽に始められますが、上述の構造的課題があるため、運用面での限界は非常に早い段階で訪れます。
向いているケース:
- ASIN数が少ない(数十品程度)
- 月次のレポーティングだけで十分
- 担当者がデータに慣れており、手動での加工に抵抗がない
限界:
- ASIN別×日別のデータを一括ダウンロードできないため、ASIN数や対象日数が増えるほど作業量が爆発的に増加する
- 返品・返金による過去データの変動に対応するには、同じデータを繰り返し取得し直す必要がある
- レポートごとにダウンロード手順や期間指定が異なるため、手順書なしでは属人化する
- 過去データの保持期限を過ぎると取得不可能になる
アプローチ2:API連携による自動収集
SP-APIやAmazon Ads APIを使って、プログラムでデータを自動取得する方法です。一度構築すれば日次で自動的にデータが蓄積されるため、手動ダウンロードの課題を根本的に解決できます。
必要な技術要件:
- OAuth 2.0認証の実装(SP-APIではLWA:Login with Amazon)
- APIレート制限への対応(リクエスト頻度の制御、リトライロジック)
- データの保管先(データベースやクラウドストレージ)の設計と構築
- エラーハンドリング(API仕様変更・一時障害への対応)
- セラーAPI / ベンダーAPIそれぞれのエンドポイントへの対応
向いているケース:
- 社内にエンジニアリソースがある
- 独自の分析基盤を構築したい
- データの取得条件や保管方法を完全にカスタマイズしたい
課題:
- 初期開発コストが高い(数百万円〜の開発費が目安)
- 返品・返金による過去データの変動に対応する再取得ロジックの設計が必要
- AmazonのAPI仕様変更への追従が継続的に必要
- セラーとベンダーでAPIの体系が異なるため、両対応の開発工数は単純に2倍以上になることがある
- 開発・運用を担うエンジニアが退職すると、システムがブラックボックス化するリスク
アプローチ3:SaaSツールの活用
Amazon分析に特化したSaaSツールを利用する方法です。APIとの連携やデータの保管・統合がすでに実装されているため、エンジニアリソースがなくても高度なデータ収集環境を構築できます。
向いているケース:
- エンジニアリソースを分析基盤の開発に割きたくない
- データ収集だけでなく、分析・レポーティング・施策実行まで一貫して行いたい
3つのアプローチの比較
| 比較項目 | 手動ダウンロード | API自社開発 | SaaSツール |
|---|---|---|---|
| 初期コスト | ほぼゼロ | 高い(開発費) | 中程度(月額費用) |
| 技術難易度 | 低い | 高い | 低い |
| スケーラビリティ | 低い(ASIN数に比例して工数増) | 高い(自動化済み) | 高い(自動化済み) |
| 保守負荷 | 毎回の手作業 | API仕様変更への追従 | 低い(ツール側が対応) |
| カスタマイズ性 | 高い(自由に加工可能) | 非常に高い | ツールの機能範囲内 |
データの保管・統合基盤を選ぶ
データを収集できたとして、それをどこに保管し、どう統合するかが次の問題です。保管基盤の選択は、データ量・分析の複雑さ・チームの技術力によって変わります。
保存すべきデータの粒度と項目
保管基盤を選ぶ前に、「どの粒度でデータを保存するか」を決めることが重要です。
Amazonで売上データと広告データを統合できる最小の共通粒度はASIN × 日別です。この粒度でデータを蓄積しておけば、週次・月次への集約はもちろん、ASIN横断の比較や期間比較など、多くの分析に汎用的に対応できます。
また、売上の増減を分析するためには、売上の「総額」だけでなく売上を構成する要素を分解して保存しておく必要があります。具体的には以下の2つの分解軸が基本です。
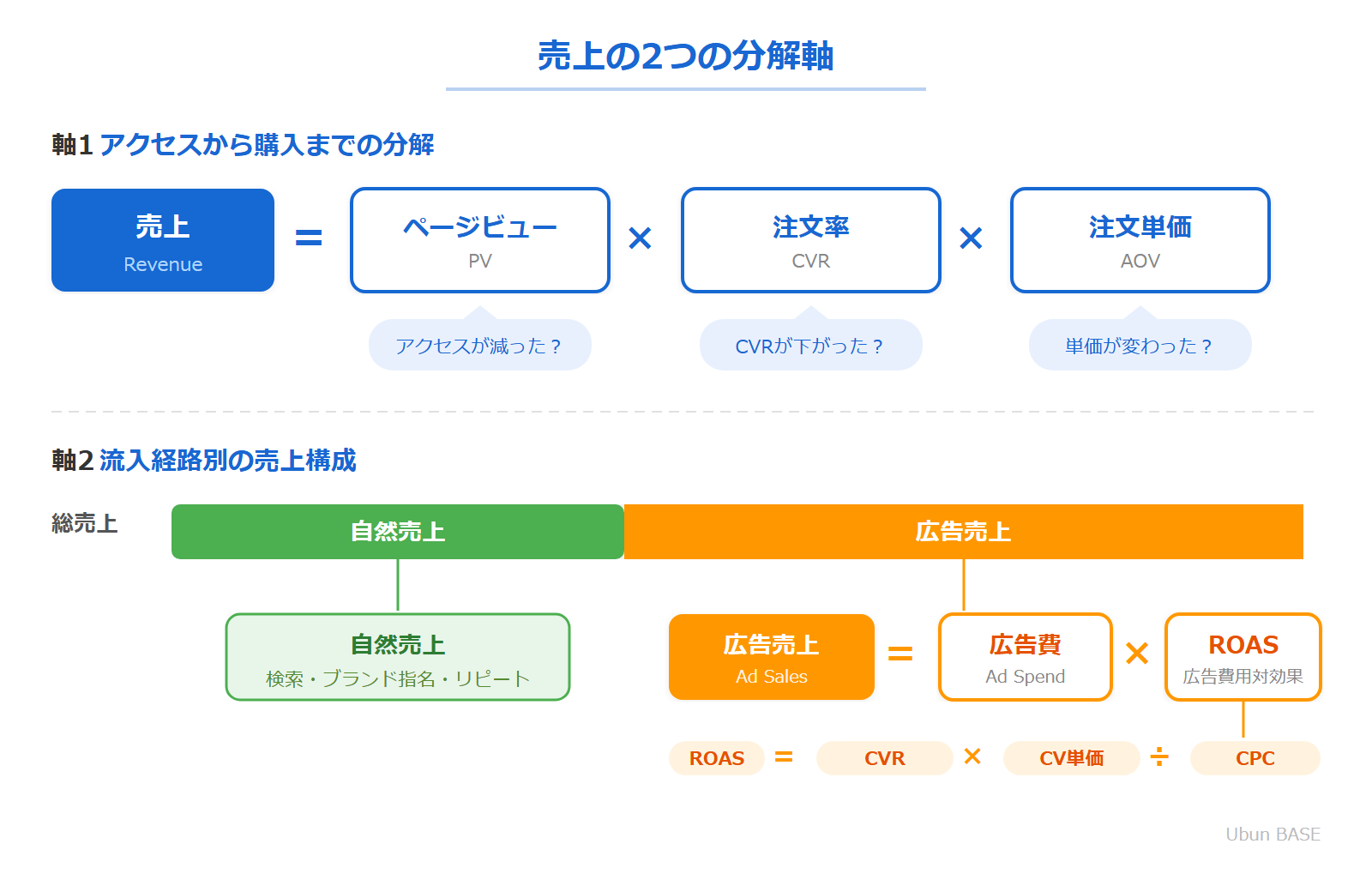
分解軸1:アクセスから購入までのファネル
売上 = ページビュー × 注文率(CVR)× 注文単価
この3要素を日別×ASIN別で保持しておけば、「売上が下がった原因はアクセス減なのか、CVR低下なのか、単価の下落なのか」を即座に切り分けることができます。
分解軸2:流入経路別の売上構成
総売上 = 自然売上 + 広告売上
広告売上はさらに以下のように分解できます。
広告売上 = 広告費 × ROAS(広告費用対効果)
ROAS = CVR × CV単価 ÷ CPC
この分解を理解しておくと、「広告売上が下がった原因はCPCの高騰なのか、CVRの低下なのか」を切り分けることができます。さらに広告売上をSP・SB・SD・DSPのチャネル別に分解して持っておけば、チャネルごとの効率の推移や広告依存度の変化も追跡できます。
これらの項目をASIN × 日別の粒度で蓄積し続けることが、分析環境の「使える度」を大きく左右します。
スプレッドシート(Google Sheets / Excel)
もっとも手軽な選択肢です。少数のASINで月次レポートを作成する程度であれば十分に機能します。
適する規模の目安:
- ASIN数:〜100程度
- データ量:数万行以下
- 更新頻度:週次〜月次
限界:
- 数万行を超えるとExcelの動作が重くなり、Google Sheetsでは500万セルの上限がある
- 複数シートの結合(VLOOKUP / INDEX-MATCH)が複雑化し、エラーが発生しやすくなる
- 同時編集やバージョン管理が難しい
データベース / DWH(データウェアハウス)
本格的な分析環境を構築するなら、データベースやDWHが必要になります。代表的な選択肢としてはGoogle BigQuery、Amazon Redshift、Snowflakeなどがあります。
メリット:
- 数億行規模のデータでも高速に処理できる
- SQLで柔軟なクロス集計・結合が可能
- データの整合性を保つ仕組み(スキーマ定義、型制約)がある
課題:
- 構築・運用にはエンジニアのスキルが必要
- クラウドサービスの利用料が発生する
- データの投入パイプライン(ETL処理)の設計と保守が必要
BIツールとの接続
保管したデータを可視化するには、BIツール(Looker Studio、Tableau、Power BIなど)との接続が有効です。ただし、BIツールはあくまで可視化のレイヤーであり、データの収集・保管・統合を代替するものではありません。
BIツールを活用するためには、その手前に「きれいに統合されたデータ」が必要です。つまり、収集 → 保管 → 統合の基盤が整ってはじめて、BIツールが力を発揮するという順序を理解しておくことが重要です。
分析環境を構築する際の5つの落とし穴
データの収集・保管・統合の仕組みを設計する際、見落とされがちなポイントがあります。環境構築に着手する前に、以下の5つの落とし穴を確認しておきましょう。
1. データ定義の不一致
Amazonの各レポートは、同じように見える指標でも定義が微妙に異なることがあります。
- 税込と税抜の違い:セラーセントラル・ベンダーセントラルの売上データは税込で計上されるのに対し、広告レポートの広告費や広告経由売上は税抜で計上される。この違いを無視してACOSやROASを計算すると、数値が正確でなくなる
- 広告売上の計上ロジック:広告レポートの売上は、広告をクリックした日に、クリックされたASINの売上として計上される。ユーザーが実際に購入した日や購入したASINとは異なる場合がある。さらにアトリビューション期間(通常7日間または14日間)の設定によっても金額が変わるため、ビジネスレポートの「注文売上」と一致しない
- ページビューの定義:セラーの「ページビュー」は該当ASINの全閲覧数、ベンダーの「グランスビュー」は自社がカートを取得している状態の閲覧数のみ。同じ「ページの閲覧数」でも母数が異なる
これらの定義差を把握せずにデータを統合すると、分析結果に矛盾が生じ、誤った判断につながるリスクがあります。環境構築の初期段階で、各データ項目の定義(税込/税抜、計上タイミング、計測条件)を「データ辞書」として明文化しておくことを強くおすすめします。
2. マスタデータの未整備
Amazonのレポートデータは、ASINやキャンペーンIDなどのコードで記録されます。これらのコードだけでは、どの商品がどのカテゴリーに属するか、どのキャンペーンがどの目的で運用されているかが一目でわかりません。分析環境を活かすには、3種類のマスタデータの整備が不可欠です。
1. 商品マスタ
- ASIN・SKU・JANの紐付け:Amazon固有のコードと社内コードを対応させる
- 親ASIN・子ASINの関係:バリエーション商品(色・サイズ違い等)をグルーピングする
- 自社カテゴリー分類(出品者カテゴリー):Amazonのカテゴリーとは別に、自社独自の分類軸で商品をグルーピングする
特に自社カテゴリー分類は、商品マスタの中でも最も重要な要素です。Amazonが提供するカテゴリーやブランドの分類は、Amazonのカタログ管理上の区分であり、自社が社内報告や経営判断で使いたい分析粒度とは一致しないことがほとんどです。
たとえば、食品メーカーがAmazonで50商品を販売している場合、Amazonのカテゴリーでは「食品・飲料・お酒」に一括りにされてしまいます。しかし社内では「ナッツ系」「チョコレート系」「ギフトセット」「定期便向け」といった自社独自の商品ラインで管理しているはずです。この分類がなければ、「ナッツ系の売上は前月比でどうか」「ギフトセットの広告効率は他ラインと比べてどうか」といった、実務で最も必要とされる粒度の分析ができません。
自社カテゴリーは階層構造(大分類→中分類→小分類)で設計しておくと、経営層への報告では大分類で俯瞰し、現場の施策検討では小分類まで掘り下げるといった使い分けが可能になります。
2. キャンペーンマスタ
Amazon広告ではキャンペーン数が数十〜数百に膨れ上がることが珍しくありません。キャンペーンIDだけでは全体像を把握できないため、以下の情報を紐づけて管理する必要があります。
- キャンペーンの目的分類:ブランド認知向け / 獲得向け / 防御(自社名キーワード)向けなど
- 対象商品・カテゴリーとの紐付け:どのキャンペーンがどの商品群に対応しているか
- 広告タイプ:SP / SB / SD / DSPのどれか
キャンペーンマスタが整備されていれば、「獲得向けキャンペーン全体のACOS」や「カテゴリーAに投下している広告費の合計」といった俯瞰的な分析が可能になります。
3. 売上目標
データを蓄積するだけでは、それが「良いのか悪いのか」を判断できません。分析環境に売上目標(予算)を組み込んでおくことで、実績との差異をリアルタイムに把握できるようになります。
- 月次売上目標:全体・カテゴリー別・商品別の売上予算
- 広告KPI目標:ACOS目標、広告費予算、ROAS目標
- 進捗率の自動計算:月の途中で「今月の目標に対して何%進捗しているか」を確認できる仕組み
目標がなければデータは単なる数字の羅列です。目標と実績を同じ環境で比較できる状態にしておくことが、データを意思決定に活かすための前提条件です。
これらのマスタデータの整備は地味な作業ですが、分析環境の土台です。マスタが整っていなければ、どれだけデータを蓄積しても「使える分析」にはなりません。
3. 過去データの取得期間制限
Amazonのレポートには、それぞれ遡れる期間に制限があります。
| データソース | 遡れる期間の目安 |
|---|---|
| ビジネスレポート(セラー) | 過去2年 |
| リテール分析(ベンダー) | 過去2年 |
| 広告レポート | 過去60日〜90日 |
| AMC | 過去12.5ヶ月 |
「昨年のプライムデーの広告データと比較したい」と思ったときに、すでにデータが取得できなくなっている――これは非常によくある失敗です。分析環境の構築を決めた時点で、できるだけ早くデータの蓄積を開始することが重要です。取得期限が過ぎたデータは二度と手に入りません。
4. APIレート制限・仕様変更への対応
API連携で自動収集を行う場合、AmazonのAPIにはリクエスト数の上限(レート制限)が設定されています。ASIN数が多い場合やレポートの種類が多い場合は、レート制限の範囲内でリクエストをスケジューリングする仕組みが必要です。
また、AmazonのAPIは比較的頻繁に仕様変更が行われます。過去には旧MWS(Marketplace Web Service)からSP-APIへの大規模な移行がありました。自社開発の場合、こうした仕様変更への追従コストを見積もっておく必要があります。
5. 属人化
分析環境の構築・運用において、最も見過ごされがちなリスクが「属人化」です。
- Excelの集計マクロが特定の担当者しか分からない
- API連携のスクリプトを書いたエンジニアが退職した
- データの定義や加工ロジックがドキュメント化されていない
これらはすべて、環境の再現性が失われることを意味します。分析環境の構築時には、手順書の整備やツールによる標準化を意識し、特定の個人に依存しない仕組みを設計することが重要です。
Ubun BASEで実現するデータ分析環境
ここまで、Amazonのデータ分析環境を構築するための全体像と、構築時に直面しがちな課題を整理してきました。これらの課題を包括的に解決するのが、Ubun BASEです。
セラー・ベンダーの両アカウントに対応
Ubun BASEは、セラーセントラルとベンダーセントラルの両方に対応しています。SP-API・Amazon Ads API(AMC APIを含む)と連携し、それぞれのチャネルのデータを自動的に収集します。セラーアカウント・ベンダーアカウントのどちらでも同じ操作性でデータを確認・分析できます。
データ収集の完全自動化
管理画面からCSVを手動でダウンロードする作業は一切不要です。売上・広告のデータはASIN×日別の粒度で日次に自動取得・蓄積されます。前述した「ASIN別×日数分のダウンロード」や「返品・返金による過去データの再取得」もすべて自動で処理されるため、データの取得漏れや更新漏れを心配する必要はありません。API仕様変更への追従もUbun BASE側で対応するため、ユーザーの保守負荷はゼロです。
自社カテゴリー(出品者カテゴリー)による柔軟な分析
Ubun BASEでは、ASIN・SKUに対して商品名・ブランドに加え、自社独自のカテゴリー分類(出品者カテゴリー)を紐づけて管理できます。前述の通り、Amazonのカテゴリーやブランド分類は自社の分析・報告粒度と一致しないことがほとんどです。Ubun BASEの出品者カテゴリーを設定すれば、自社の商品ライン・事業部・ブランド戦略に合わせた粒度で売上・広告・利益のすべてのレポートを集計・比較できます。
AMCレポートの自動実行
通常であればSQLの知識が必要なAMCの分析も、Ubun BASEでは設定するだけで自動的にレポートが生成されます。リピート分析、ARPU/LTV分析、RFM分析、新規顧客分析など、マーケティングに直結するレポートを専門知識なしで活用できます。AMCオーディエンスの作成もワンクリックで実行できるため、分析結果を広告施策にすぐに反映できます。
環境構築から分析・施策実行まで
Ubun BASEは「データ収集・保管・統合」の環境構築だけでなく、その先の「分析」「施策実行」までをカバーするプラットフォームです。売上・利益・広告のレポート自動生成、AIによるインサイト分析、広告の自動入札など、データ活用のサイクル全体を一つのツールで完結できます。
構築した分析環境をどのように分析やアウトプットに活用するかについては、続編の「分析・アウトプット編」で詳しくご紹介します。
まとめ
Amazonのデータ分析で成果を出すには、分析手法の前に「分析環境」の整備が必要です。本記事のポイントを振り返ります。
- データソースは多岐にわたる:セラーセントラル、ベンダーセントラル、Amazon広告コンソール、AMCなど、取得元が分散しており、セラーとベンダーでデータの定義も異なる(ページビュー、売上の基準など)
- 収集方法は3つ:手動ダウンロード、API自社開発、SaaSツール活用。組織のリソースと規模に応じた選択が必要
- ASIN×日別の粒度で蓄積する:売上と広告データを統合できる最小粒度。ページビュー・注文率・注文単価、自然売上・広告売上の構成要素を分解して保存しておくことが分析の鍵
- AMCはモニタリング指標を定期蓄積:新規/既存売上、N-CPA、リピート率、LTVなどAMCでしか取れない指標を定期的に蓄積し、スポット分析は都度実行する使い分けが効率的
- 5つの落とし穴に注意:税込/税抜の違い、広告売上の計上ロジック、マスタデータ(商品・キャンペーン・売上目標)の未整備、過去データの取得期限、属人化
- 早く始めるほど有利:過去データは取得期限を過ぎると二度と手に入らない。環境構築を決めた時点でデータの蓄積を開始すべき
Ubun BASEは、セラー・ベンダー両対応のデータ収集自動化、商品マスタ管理、AMCレポート自動生成まで、分析環境の構築をワンストップで実現します。「まずはデータを貯めるところから始めたい」という方は、ぜひUbun BASEの導入をご検討ください。

株式会社ウブン PdM of UbunBASE
2007年に株式会社オプトに入社し、金融業界向けインターネット広告の提案・運用を担当。株式会社電通に出向し、大手ナショナルクライアントのデジタルメディア戦略の立案と実行に従事。2012年にオプトに帰任後、DSPや広告効果測定ツールのプロダクトマネージャーを歴任。グループ会社のスキルアップビデオテクノロジーズでは取締役として動画広告のアドテクノロジー事業を推進。2020年に株式会社ウブンに参画し、Amazonレポートの自動化ツール「Ubun BASE」を立ち上げ、開発とマーケティングを統括。


